
프로세스
프로세스 개념
일괄저리 시스템은 잡(Job) 들을 실행하는 반면세, 시분할 시스템은 사용자 프로그램 또는 태스크(Task) 를 가진다. 이와같은 것들을 프로세스(Process) 라고 한다.
프로세스(Process)
프로세스란 실행중인 프로그램이다.
프로세스는 텍스트 세션 으로 알려진 프로그램 코드 영역과, 프로그램 카운터 의 값과 처리지 레지스터의 내용으로 대표되는 현재 활동을 포함한다. 프로세스는 일반적으로 함수의 매개변수, 복귀주소, 로컬 변수와 같은 임시적인 자료를 가지는 프로세스 스택(Stack) 영역과 전역변수들을 수록하는 데이터 섹션 을 포함한다. 또한 프로세스 실행중 동적으로 할당되는 메모리인 힙(Heap) 을 포함한다.
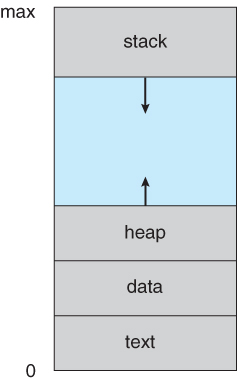 |
|---|
| 메모리상의 프로세스 |
- 스택영역은 높은 주소로 부터 낮은 주소로 데이터가 기록한다.
- 힙역역은 낮은 주소로 부터 높은 주소로 데이터를 기록한다.
- 스택영역과 힙영역은 같은 영역을 공유하고 있으며 이는 가변적이다.
- 텍스트영역과 데이터역역은 크기가 고정적이다.
프로세스 상태(Process State)
프로세스는 실행되면서 그 상태가 변경된다.
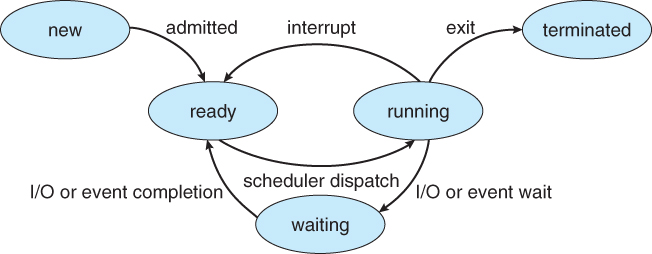 |
|---|
| 프로세스 상태도 |
- New
- 프로세스가 생성 중이다.
- Ready
- 프로세스가 처리기에 할당되기를 기다리는 중이다.
- Running
- 프로세스가 실행되고 있는 중이다.
- Waiting
- 프로세스가 어떠한 이벤트를 기다리는 중이다.
- Terminated
- 프로세스의 실행이 종료된다.
어느 한 순간에 한 처리기상에서는 오직 하나의 프로세스만이 실행 된다. 즉 많은 프로세스가 Waiting 및 Ready 상태에 있다.
프로세스 제어블록(Process Control Block)
 |
|---|
| 프로세스 제어 블록(PCB) |
- 프로세스 상태(Process State)
- 상태는 New, Ready, Running, Waiting, Terminated 가 있다.
- 프로그램 카운터(Program Counter)
- 이 프로세스가 다음에 실행할 명령어의 주소를 가리킨다.
- 나중에 프로세스가 계속해서 정상적으로 실행될 수 있도록 인터럽트 발생 시, 저장되어야 한다.
- 추후 이 프로세스가 다시 실행 될때, 백업을 받은 후, 프로그램 카운터가 가리키는 부분부터 실행
- CPU 레지스터들(CPU Registers)
- 누산기, 인덱스 레지스터, 스택 레지스터, 범용 레지스터등 다양한 타입의 CPU 레지스터의 상태 코드를 포함한다.
- 프로그램 카운터와 함께 이 상태 정보는 나중에 프로세스가 계속해서 정상적으로 실행될 수 있도록 인터럽트 발생시, 저장되어야 한다.
- 추후 이 프로세스가 다시 실행 될때, 백업을 받은 후, 중지한 부분부터 실행
- CPU 스케쥴링 정보(CPU Scheduling Infomation)
- 프로세스 우선순위, 스케쥴 큐에 대한 포인터와 다른 스케쥴 매개변수들을 포함한다.
- 메모리 관리 정보(Memory Management Infomation)
- OS에 의해 사용되는 메모리 관리 시스템에 따라 기준 레지스터와 한계 레지스터의 값과 같은 정보를 포함한다.
- OS에 의해 사용되는 메모리 관리 시스템에 따라 페이지 테이블 또는 세그먼트 테이블 등과 같은 정보를 포함한다.
- 회계 정보(Accounting Infomation)
- CPU 사용 시간과 경과된 실시간, 시간 제한, 제정 정보, 프로세스 번호 등을 포함한다.
- 입출력 상태 정보(I/O State Infomation)
- 프로세스에 의해 할당된 입출력 장치들과 열린 파일의 목록 등을 포함한다.
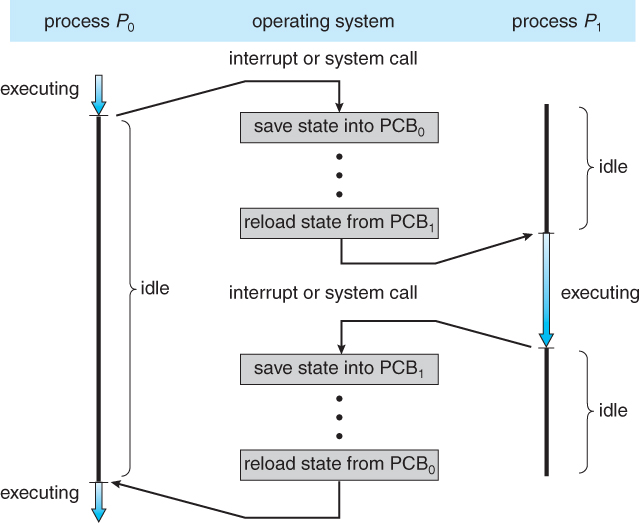 |
|---|
| 프로세스에서 다른 프로세스로 CPU가 전환되는 흐름도 |
스레드(Thread)
현대의 대부분의 OS는 프로세스의 개념을 확장하여 한 프로세스가 다수의 실행 스레드를 가질 수 있도록 허용한다. 즉, 하나의 프로세스가 다수의 스레드를 가짐으로서 하나 이상의 일을 수행 할 수 있도록 한다.
스레드를 지원하는 시스템에서의 PCB 는 각 스레드에 관한 정보를 포함하도록 확장된다.
프로세스 스케쥴링
다중 프로그래밍의 목적은 CPU 이용을 최대화 하기 위해 항상 어떤 프로세스가 실행되도록 하는데 있다. 시분할의 목적은 각 프로그램이 실행되는 동안 사용자가 상호 작용할 수 있도록 프로세스들 사이에서 CPU를 빈번하게 교체하는 것이다. 이러한 목적을 달성하기 위해 프로세스 스케쥴러(Process Scheduler) 는 CPU에서 실행 가능한 여러 프로세스등 중에서 하나의 프로세스를 선택하여 실행한다.
 |
|---|
| Linux에서의 프로세스 표현 |
스케쥴링 큐(Scheduling Queue)
프로세스가 시스템에 들어오면, 이들은 잡 큐(Job Queue) 에 놓여진다. 이 큐는 시스템 안의 모든 프로세스로 구성되어 있다. 주 메모리에 존재하며, 준비 완료 상태(Ready State)에서 실행을 대기하는 프로세스들은 준비 완료 큐(Ready Queue) 라 불리는 리스트 상에 유지된다.
Ready Queue는 일반적으로 Linked List로 저장되어 지며, Ready Queue의 헤더는 리스트의 첫번째와 마지막 PCB를 가리키는 포인터를 포함한다. 각 PCB는 Ready Queue에 있는 다음 프로세스를 가리키는 포인터 필드를 가진다.
특정 입출력 장치를 대기하는 프로세스들의 리스트를 장치 큐(Device Queue) 라고 한다.
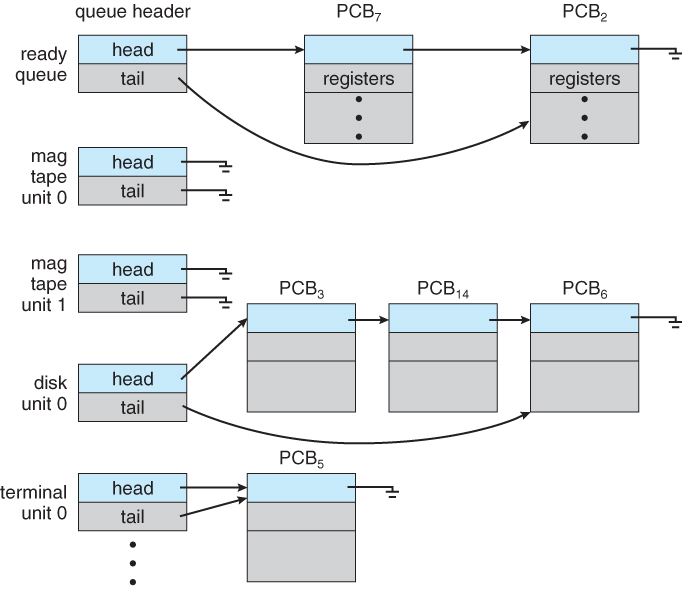 |
|---|
| Ready Queue와 다양한 Device Queue |
프로세스 프케쥴링의 공통적인 표현 방신은 아래와 같은 큐잉 도표(Queueing Diagram) 이다.
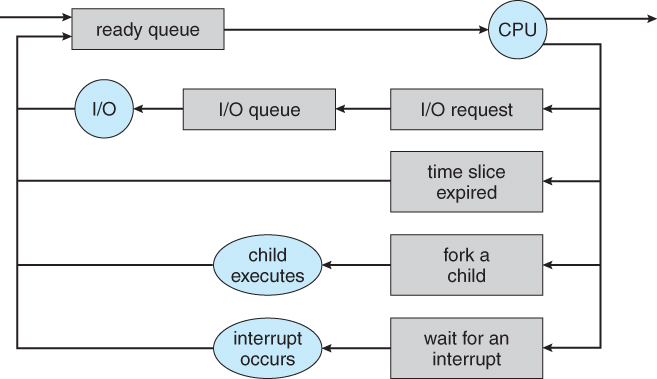 |
|---|
| 프로세스 스케쥴링을 표현하는 Queueing 도표 |
새로운 프로세스는 처름에 Ready Queue에 놓인다. 프로세스는 실행을 위해 선택될 때, 즉 CPU를 할당받을(Dispatch) 때 까지 Ready Queue에서 대기한다. 일단 프로세스에 CPU가 할당되어 실행되며느 여러가지 일중 하나가 발생할 수 잇다.
- 프로세스가 입출력 요청을 하여 입출력 큐에 넣어질수 있다.
- 프로세스가 새로운 자식 프로세스를 생성하고 자식 프로세스의 종료를 기다릴 수 있다.
- 프로세스가 인터럽트의 결과에 의해 강제로 CPU로부터 제거되고, Ready Queue에 다시 놓여질 수 있다.
프로세스는 종료될 때까지 이 주기를 반복하며, 종료되면 모든 큐에서 삭제되고 그 자신의 PCB와 자원을 반납한다.
스케쥴러(Schedulers)
프로세스는 일생동안에 다양한 스케쥴링 큐들 사이를 여행한다. OS는 어떤 방식으로든지 스케쥴링 목적을 위해 프로세스들을 큐에서 반드시 선택해야 한다. 선택절차는 적절한 스케쥴러(Schedulers) 에 의해 선택된다.
프로세스들은 대용량 메모리(전형적으로 디스크)에 저장되어 나중에 실행될 때 까지 유지된다.
장기 스케쥴러(Long-term Scheduler) 또는 잡 스케쥴러 는 이 디스크에서 프로세스들을 선택하여 실행 하기 위해 메모리로 적재한다. 단기 스케쥴러(Short-term Scheduler) 또는 CPU 스케쥴러 는 실행 준비가 완료되어 있는 프로세스들 중에서 선택하여, 이들 중 하나에게 CPU를 할당한다.
장기 스케쥴러는 다중 프로그래밍 정도(메모리에 있는 프로세스들의 수) 를 제어한다. 즉 몇개의 프로세스를 메모리에 적재 시킬 것인지 제어한다.
입출력 중심의 프로세스 는 연산보다 입출력 실행에 더 많은 시간을 소요하는 프로세스 이다. 반면에 CPU 중싱 프로세스 는 입출력 중심 프로세스보다 연산에 시간을 더 소요하여, 입출력 요청을 드물게 발생시키는 프로세스 이다.
장기 스케쥴러는 입출력 중심과 CPU 중심 프로세스들의 적절한 프로세스 혼합(mix) 을 선택하는 것이 중요하다.
UNIX와 Windows와 같은 시분할 시스템들은 장기 스케쥴러가 없으며, 모든 새로운 프로세스를 단기 스케쥴러를 위해 단순히 메모리에 넣는다.
시분할 시스템과 같은 일부 OS들은 추가로 중간수준의 스케쥴링, 즉 중기 스케쥴러(Medium-term Scheduler) 를 가진다.
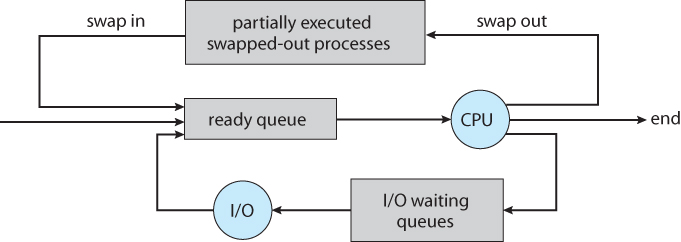 |
|---|
| Queueing 도표에 중기 스케쥴링을 포함 |
중기 스케쥴어의 핵심 아이디어는 메모리에서 프로세스들을 제거함으로써 다중 프로그래밍의 정도를 완화하는 것이 가끔 바람직할 수 있다는 것이다. 즉 차후에 다시 프로세스를 메모리로 불러와서 중단되었던 지점에서 실행을 재개한다. 이러한 기법을 스와핑(Swapping) 이라 한다. 프로세스는 중기 스케쥴러에 의해 스왑되어 다가고 다시 스왑되어 들어온다.
문맥교환(Context Switch)
인터럽트가 발생하면 시스템은 인터럽트 처리가 끝난 후에 문맥(Context) 을 복구할 수 있도록 현재 실행 중인 프로세스의 현재 문맥을 저장할 필요가 있다.
문맥은 프로세스의 PCB에 표현된다.
문맥은 CPU의 레지스터 값, 프로세스 상태, 메모리 관리 정보 등을 포함한다.
일반적으로 커널 모드이건, 사용자 모드이건 CPU의 현재 상태를 저장하는 작업을 수행하고(State Save), 나중에 연산을 재개하기 위해 상태 복구 작업을 수행한다(State Restore).
CPU를 다른 프로세스로 교환하려면 이전의 프로세스의 상태를 보관하고 새로운 프로세스의 보관된 상태를 복구하는 작업이 필요하다. 이 작업을 문맥 교환(Context Switch) 라고 한다.
문맥 교환이 일어나면 커널은 과거 프로세스의 문맥을 PCB에 저장하고, 선택된 새로운 프로세스의 저장된 문맥을 복구한다.
문맥 교환이 진행될 동안 시스템이 아무런 유용한 일을 하지 못하기 때문에 문맥 교환 시간은 순수한 오버헤드 이다.
프로세스에 대한 연산
대부분 시스템 내의 프로세스들은 병행 실행될 수 있으며, 반드시 동적으로 생성되고 제거 되어야 한다.
기본적으로 부모 자식간의 프로세스라도 하더라도 프로세스는 서로 독립적이다.
프로세스 생성(Process Creation)
생성하는 프로세스를 부모 프로세스(Parent Process)라고 하고, 생성되는 프로세스를 자식 프로세스(Child Process) 라고 한다. 즉 프로세스는 다른 프로세스를 생성할 수 있으며 그 결과, 프로세스의 트리를 형성한다.
대부분의 현대의 OS들은 유일한 프로세스 식별자(PID) 를 사용해 프로세스를 구분하는데, 일반적으로 특정 정수를 각 프로세스에 할달하여 프로세스에게 고유한 값을 가지도록 한다.
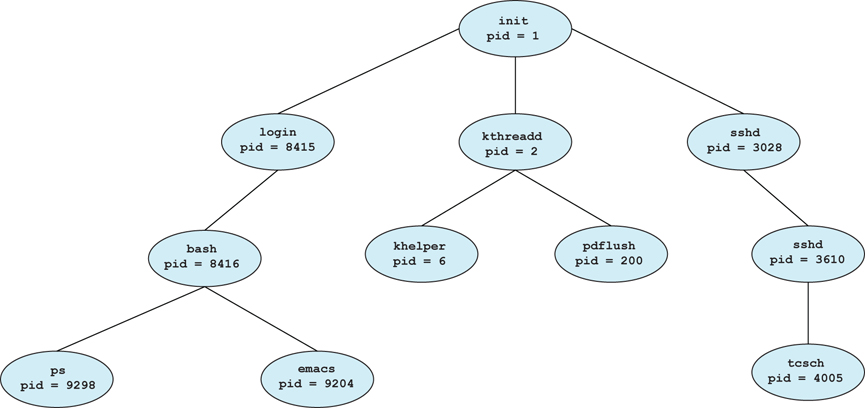 |
|---|
| 일반적은 Linux 시스템의 프로세스 트리 |
일반적으로 프로세스가 자식 프로세스를 생성할 때, 그 자식 프로세스는 자신의 일을 달성하기 위해 어떤 자원(CPU 시간, 메모리, 파일, 입출력 장치 등)이 필요하다. 자식 프로세스는 이 자원을 OS로 부터 직접 얻거나, 부모 프로세스가 가진 자원의 부분 집합만을 사용하도록 제한될 수 있다. 부모 프로세스는 자원을 분할하여 자식 프로세스들에게 나우어 주거나 메모리나 파일과 같은 몇몇 자원들은 자식 프로세스들이 같이 사용하게 할 수도 있다.
프로세스가 새로운 프로세스를 생성할 때, 두 프로세스를 실행시키는 데 두 가지 가능한 방법이 존재한다.
- 부모는 자식과 병행하게 실행을 계속한다.
- 부모는 일부 또는 모든 자식이 실행을 종료할 때까지 기다린다.
새로운 프로세스들의 주소 공간 측면에서 볼대 아래와 같이 두가지 가능성이 있다.
- 자식 프로세스는 부모 프로세스의 복사본이다.(자식 프로세스는 부모와 똑같은 프로그램과 데이터를 가진다.)
- 자식 프로세스가 자신에게 적재될 새로운 프로그램을 가지고 있다.
 |
|---|
| Linux의 fork() 시스템 콜을 통한 프로세스 생성 |
프로세스 종료(Process Termination)
프로세스 종료에는 크게 두가지가 있다.
- 프로세스가 마지막 문장의 실행을 끝내고, exit 시스템 호출을 사용하여 OS에게 자신의 삭제를 요청한다.
- 한 프로세스는 적당한 시스템 호출을 통해, 다른 프로세스의 종료를 유발할 수 있다. 일반적으로, 그런 시스템 호출은 단지 종료될 프로세스의 부모만이 호출할 수 있다.
프로세스간 통신
OS내에서 실행되는 병행 프로세스들은 독립적 이거나 협력적 인 프로세스들 일수 있다.
프로세스 협렵을 허용하는 환경을 제공하는 데는 아래와 같은 이유가 있다.
- 정보 공유(Information Sharing)
- 여러 사용자가 동일한 정보(ex 공유 파일)에 접근할 경우가 있을수 있으므로, 그러한 정보를 병행적으로 접근할 수 있는 환경을 제공해야 한다.
- 계산 가속화(Computation Accelation)
- 특정한 태스크를 여러 서브 태스크로 나누어, 각각이 다른 서브 태스크들과 병렬로 실행되도록 한다.
- 다수의 처리 코어를 가져야만 가능하다.
- 모듈성(Modularity) -시스템의 기능을 별도의 프로세스들 또는 스레들로 나누어, 모듈식 형태로 시스템을 구성하도록 한다.
- 편의성(Convenience)
- 개별 사용자들이 한 순간에 작업할 많은 태스크를 가질 수도 있다.
위와 같은 협렵적 프로세스들은 데이터와 정보를 교환할 수 있는 프로세스간 통신(InterProcess Communication) 기법을 필요로 한다.
프로세스간 통신에는 기본적으로 공유 메모리(Shared Memory) 와 메시지 전달(Message Passing), 두가지 방식이 있다.
- Shared Memory model
- 협력 프로세스들에 의해 공유되는 메모리 영역이 구축된다.
- 공유 메모리 영역을 구축할 때만 시스템 콜이 필요하다. 공유 메모리 영역이 구축되면, 모든 접근은 일반적인 메모리 접근으로 취급되어 커널의 도움이 필요없다.
- 메시지 전달 방식보다 빠르다.
- 멀티코어 시스템에서 공유 메모리는 공유 데이터가 여러 캐시 사이에서 이주하기 때문에 발생하는 캐시 일관성 문제로 인해 성능 저하가 발생한다.
- Message Passing model
- 협력 프로세스들 사이에 통신을 통해 메시지를 교환하여 이루어 진다.
- 충돌을 회피할 필요가 없기 때문에 적은 양의 데이터를 교환하는데 유용하다.
- 공유 메모리 방식보다 구현이 용이하다.
- 메시지를 전달할때, 통상적으로 시스템 콜을 사용하여 구현되므로, 커널 간섭 등의 부가적인 시간 소비 작업이 필요하다.
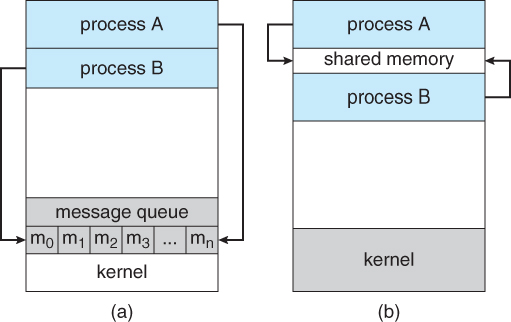 |
|---|
| 통신 모델. (a) 메시지 전달. (b) 공유 메모리 |
 |
|---|
| 다중프로세스 구조 - Chrome 브라우저 |
공유 메모리 시스템(Shared Memory System)
통상 공유 메모리 영역은 공유 메모리 세그먼트를 생성하는 프로세스의 주소 공간에 위치한다. 이 공유 메모리 세그먼트를 이용하여 통신하고자 하는 다른 프로세스들은 이 세그먼트를 자신의 주소 공간에 추가하여야 한다.
프로세스들은 동시에 동일한 위치에 쓰지 않도록 책임져야 한다.
생산자와 소비자가 반드시 동기화(Synchronize) 되어야 생산되지도 않은 항목들을 소비자가 소비하려도 시도하지 않을 것이다.
일반적으로 두 가지 유형의 버퍼가 사용된다.
- 무한 버퍼(Unbounded Buffer)
- 생산자 소비자 문제 에서는 버퍼의 크기에 실질적인 한계가 없다.
- 유한 버퍼(Bounded Buffer)
- 버퍼의 크기가 고정되어 있으므로, 버퍼가 비어있다면 소비자는 반드시 대기하여야 하며, 버퍼가 가득 찼으면 생산자가 대기하여야 한다.
1
2
3
4
5
6
7
8
9
10
// 공유 메모리 사이의 유한 버퍼
#define BUFFER_SIZE 10
typedef struct {
. . .
} item;
item buffer[ BUFFER_SIZE ];
int in = 0;
int out = 0;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 공유 메모리를 사용한 생산자 프로세스
item nextProduced;
while( true ) {
/* Produce an item and store it in nextProduced */
nextProduced = makeNewItem( . . . );
/* Wait for space to become available */
while( ( ( in + 1 ) % BUFFER_SIZE ) == out )
; /* Do nothing */
/* And then store the item and repeat the loop. */
buffer[ in ] = nextProduced;
in = ( in + 1 ) % BUFFER_SIZE;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 공유 메모리를 사용한 소비자 프로세스
item nextConsumed;
while( true ) {
/* Wait for an item to become available */
while( in == out )
; /* Do nothing */
/* Get the next available item */
nextConsumed = buffer[ out ];
out = ( out + 1 ) % BUFFER_SIZE;
/* Consume the item in nextConsumed
( Do something with it ) */
}
메시지 전달 시스템(Message Passing System)
메시지 전달 시스템은 최소한 두가지 연산을 제공한다.
- Send
- Receive
하나의 링크과 send()/receive() 연산을 논리적으로 구현하는 다수의 방법은 아래와 같다.
- 직접 또는 간접 통신
- 동기식(Sync) 도는 비동기식(Async) 통신
- 자동 도는 명시적 버퍼링
명명(Naming)
통신을 원하는 프로세스들은 서로를 가리킬 수 있는 방법이 있어야 한다. 이들은 간접통신 또는 직접통신을 할 수 있다.
직접 통신
직접통신 하에서, 통신을 원하는 각 프로세스는 통신의 수신자 또는 송신자의 이름을 명시해야 한다.
- send(P, message)
- 프로세스 P에게 메시지를 전송한다.
- receive(Q, message)
- 프로세스 Q에게 메시지를 수신한다.
이 기법에서 통신 연결은 다음과 같은 특성을 가진다.
- 통신을 원하는 각 프로세스의 쌍들 사이에 연결이 자동적으로 구축된다. 프로세스들은 통신하기 위해 서로 상대방의 신원만 알면 된다.
- 연결은 정확히 두 프로세스들 사이에만 연관된다.
- 통신하는 프로세스들의 각 쌍 사이에는 정확하게 하나의 연결이 존재해야 한다.
이 기법은 주소 방식에서 대칭성 을 보인다. 즉, 송신자와 수신자 프로세스가 모두 통신 하려면 상대방의 이름을 제시하여야 한다.
이 기법의 변형으로서 주소 지정 시에 비대칭 을 사용할 수 있다. 송신자만 수신자 이름을 지명하며, 수신자는 송신자의 이름을 제시할 필요가 없다.
- send(P, message)
- 메시지를 프로세스 P에 전송한다.
- receive(id, message)
- 임의의 프로세스로 부터 메시지를 수신한다. 변수 id는 통신을 발생시킨 프로세스의 이름으로 설정된다.
간접 통신
메시지들은 메일 박스(Mailbox) 또는 포트(Port)로 송신되고, 그곳으로부터 수신된다.
메일박스는 추상적으로, 프로세스들에 의해 메시지들이 넣어지고, 메시지들이 제거될 수 있는 객체하라고도 볼 수 있다.
- send(A, message)
- 메시지를 메일박스 A로 송신한다.
- receive(A, message)
- 메시지를 메일박스 A로 부터 수신한다.
동기화(Synchronization)
프로세스간 통신은 send와 receive 프리미티브에 대한 호출에 의해 발생한다.
메시지 전달은 봉쇄형(Blocking) 이거나 비봉쇄형(Non Blocking) 방식으로 전달된다.
- Blocking Send
- 송신하는 프로세스는 메시지가 수신 프로세스 또는 메일박스에 의해 수신될 때까지 block 된다.
- Non Blocking Send
- 송신하는 프로세스가 메시지를 보내고 이후 작업을 재개 한다.
- Blocking Receive
- 메시지가 이용 가능할 때까지 수신 프로세스가 block 된다.
- Non Blocking Receive
- 송신하는 프로세스가 유효한 메시지 도는 null을 받는다.
 |
|---|
| 메시지 전달을 사용한 소비자 프로세스 |
버퍼링(Buffering)
통신하는 프로세스들에 의해 교환되는 메시지는 임시 큐에 들어 있다.
- 무용량(Zero Capacity)
- 링크는 자체 안에 대기하는 메시지들을 가질수 없다.
- 송신자는 수신자가 메시지를 수신할 때 까지 기다린다.
- 유한 용량(Bounded Capacity)
- 큐는 유한한 길이 n을 가진다.
- 큐가 가득 차게되면 송신자는 큐 안이 이용 가능할 때까지 봉쇄되어야 한다.
- 무한 용량(Unbounded Capacity)
- 큐는 잠재적으로 무한한 길이를 가진다.
- 송신자는 결코 봉쇄되지 않는다.