
Replication
분산 시스템을 사용함으로써 얻을 수 있는 또 다른 이점은 가용성(availability) 이다. 가용성(availability) 은 시스템의 일부에 장애가 발생하더라도 시스템이 지속적으로 기능을 유지할수 있는 능력을 말한다. 이러한 가용성을 달성하기 위해 사용되는 기술은 복제(Replication) 가 있다.
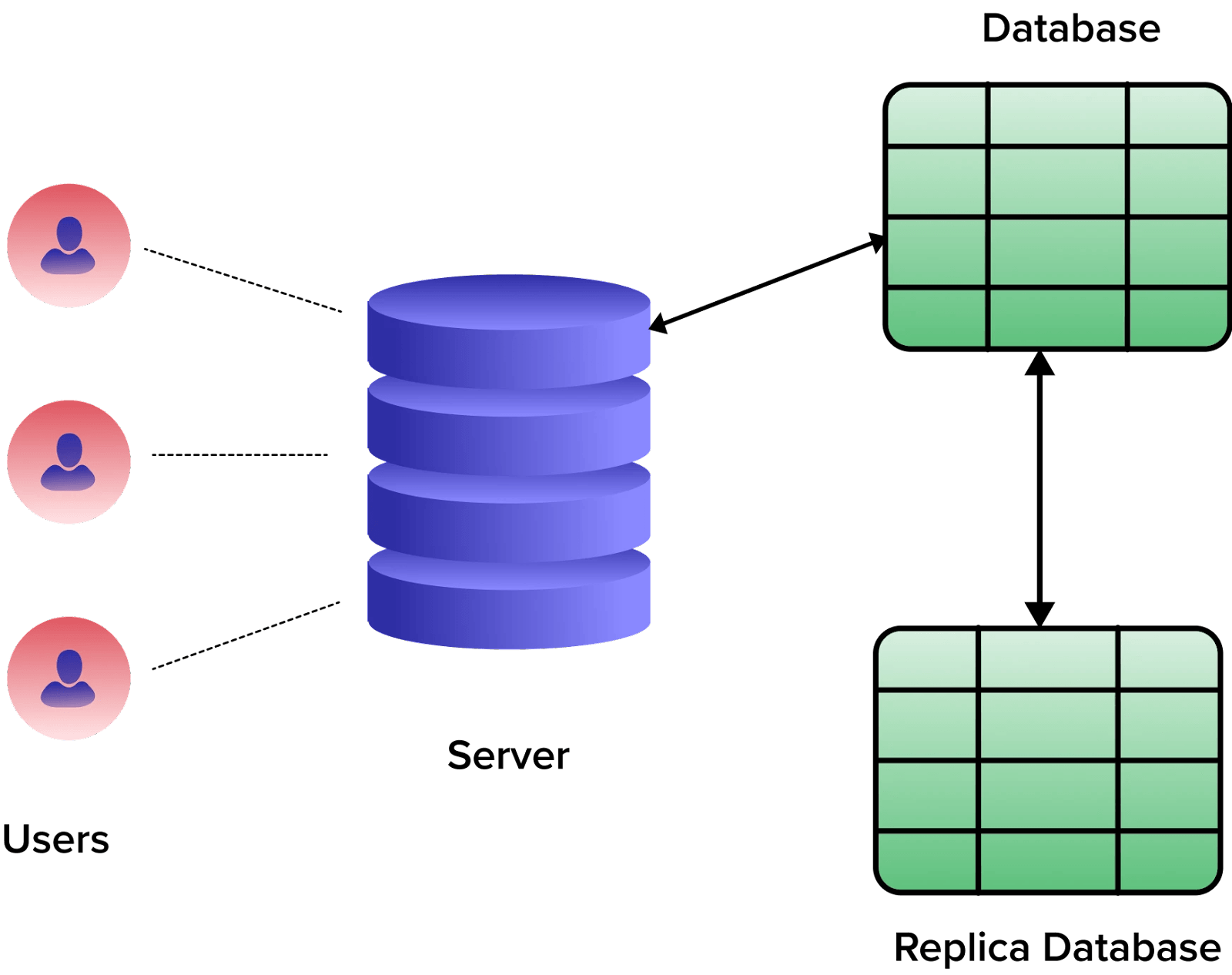
복제 는 이름 그대로 특정 노드에 대한 복제본을 생성하여 동일한 데이터를 소유하도록 하여 노드에 장애가 발생하더라도 데이터가 손실되지 않고 다른 노드에서 요청을 처리할 수 있도록 구성한다.
그러나 복제를 통해 가용성이 향상된다는 이점에는 여러 가지 새로운 문제가 발생할 수 있다. 복제는 이제 시스템에 모든 데이터 조각의 여러 복사본이 있음을 의미한다. 그러므로 이러한 복사본은 업데이트할 때마다 서로 동기화되고 유지되어야 한다.
이러한 복제를 구현하는데 크게 두가지 주요 전략이 존재한다.
- 비관적 복제(Pessimistic replication)
- 데이터 복사본이 하나만 있는 것처럼 처음부터 모든 복제본이 서로 동일함을 보장함
- 낙관적 복제(Optimistic replication)
- 서로 다른 복제본이 존재할 수 있음
Primary-Backup Replication Algorithm
Primary-Backup Replication 알고리즘은 복제본 중 노드중 하나를 리더 또는 기본 으로 지정하는 방법이다. 일반적으로 리더 이외의 나머지 복제본을 팔로워 혹은 슬레이브라고 부르며 이들은 읽기 요청만 처리하도록 한다.
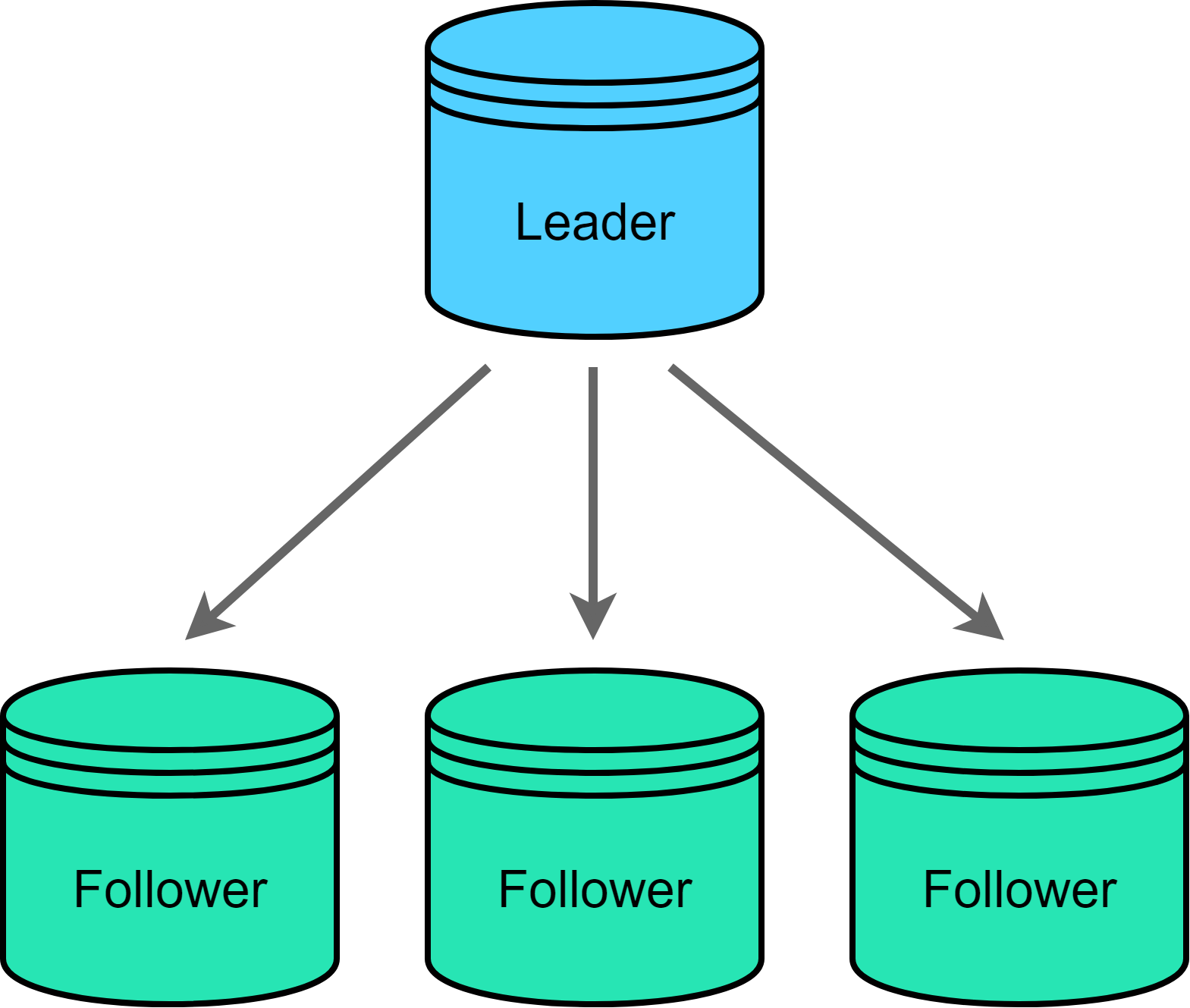
- 장점
- 구현하기 간단함
- 리더 노드에 직렬화된 동시 작업을 사용하여 트랜잭션 작업을 쉽게 지원할 수 있음
- 읽기 복제본을 추가하여 읽기 위주의 워크로드에 맞게 확장이 용이함
- 단점
- 리더의 용량에 따라 쓰기 용량이 결정되므로 쓰기가 많은 워크로드에 대해선 확작성이 떨어짐
- 성능, 내구성, 일관성 사이에 균형이 필요함
- 팔로어 노드를 더 추가하여 읽기 용량을 확장하여 업데이트를 수신하는 팔로어 수가 많은 경우 리더 노드의 네트워크 대역폭에 병목 현상이 발생할 수 있음
복제본 업데이트를 각 팔로워들에게 전파하는 방법에는 동기식과 비동기식 두가지로 나눌수 있다.
동기식 복제
동기식 복제 에서 노드는 클라이언트에 응답하여 업데이트가 완료되었음을 알린다. 이는 다른 복제본으로부터 로컬 스토리지에서도 업데이트를 수행했다는 승인을 받은 후에만 클라이언트에게 응답하도록 한다.
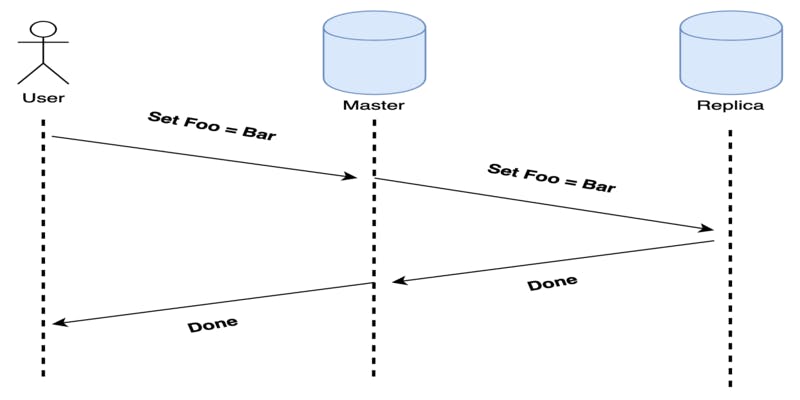
동기식 복제를 통해 내구성이 향상될수 있다. 리더가 충돌하더라도 이미 팔로워들은 데이터의 업데이트가 완료되어 데이터가 손실되지 않기 때문이다.
그러나 팔로워에게 까지 데이터를 업데이트 하므로 쓰기 요청이 느려질 수 있다. 리더는 모든 레플리카로부터 응답을 받을 때까지 기다려야 하기 때문이다.
비동기식 복제
비동기식 복제에서 노드는 다른 복제본의 응답을 기다리지 않고 로컬 저장소에서 업데이트를 수행하자마자 클라이언트에 응답한다.

비동기식 복제는 클라이언트가 더 이상 다른 복제본에 대한 네트워크 요청을 기다리지 않기 때문에 쓰기 요청의 성능을 크게 향상시킬수 있다.
그러나 이로인해 데이터의 일관성이 감소하고 내구성이 저하된다.
Multi-Primary Replication Algorithm
Multi-Primary Replication는 데이터의 일관성 보다 높은 가용성이 중요할때 사용되는 방법이다.
Multi-Primary Replication 에선 모든 노드들이 동일하며 쓰기 요청을 할수 있다. 또한 데이터 수정시 이를 나머지 노드들에게 전파하는 작업도 수행한다. 그러므로 쓰기 요청이 모든 노드에서 동시에 처리되므로 요청을 직렬화하고 단일 순서를 적용하는 단일 리더 노드가 존재하지 않는다. 이는 노드에서 처리하는 일부 요청이 올바른 순서로 처리되지 않을 수 있음을 의미 한다. 이러한 문제를 conflict 라고 부른다.

이러한 conflict 해결에 대한 일반적인 접근 방식은 다음과 같다.
- 클라이언트에게 conflict 해경 발법 공개
- conflict 발생시 사용 가능한 여러 버전의 데이터를 클라이언트에게 반환하고 클라이언트는 이중 올바른 버전을 선택하여 이를 시스템에 반영함
- 마지막 쓰기를 우선시 하여 conflict 해결
- 시스템의 각 노드는 로컬 시계를 사용하여 타임스탬프로 각 버전에 태그를 지정하고 가장 최신의 타임스탬프가 있는 버전을 선택함
- 여러 노드들의 시간이 전역적으로 동기화 되지않으면 예상치 못한 동작이 발생할 수 있음
- 인과관계 추적 알고리즘
- 두 쓰기(A, B) 사이에 충돌이 있고 하나가 다른 쓰기의 원인으로 판단되면(A가 B의 원인이라고 가정) 결과 쓰기(B)가 유지
- 요청이 동시 발생한다면 인과관계가 없는 쓰기가 존재할 수 있으며 이러한 경우 시스템은 쉽게 결정을 내릴수 없음
Quorums in Distributed Systems
동기 복제에 장애가 발생하면 노드가 복구될 때까지 시스템이 쓰기를 처리할 수 없기 때문에 쓰기 작업의 가용성이 매우 떨어지게 된다.
이러한 문제를 해결하기 위해 역방향 전략을 사용할 수 있다. 즉, 쓰기 작업을 담당하는 노드에만 데이터를 쓰지만, 읽기 작업은 모든 노드에서 최신 값을 반환하는 방식으로 처리 할 수 있다. 이렇게 하면 쓰기 가용성이 크게 증가 하지만 동시에 읽기 가용성이 감소하게 된다. 따라서 쓰기 가용성과 읽기 가용성간 균형을 이루기 위한 메커니즘이 존재하게 되는데, 쿼럼(Quorums) 을 사용하는 것이다.
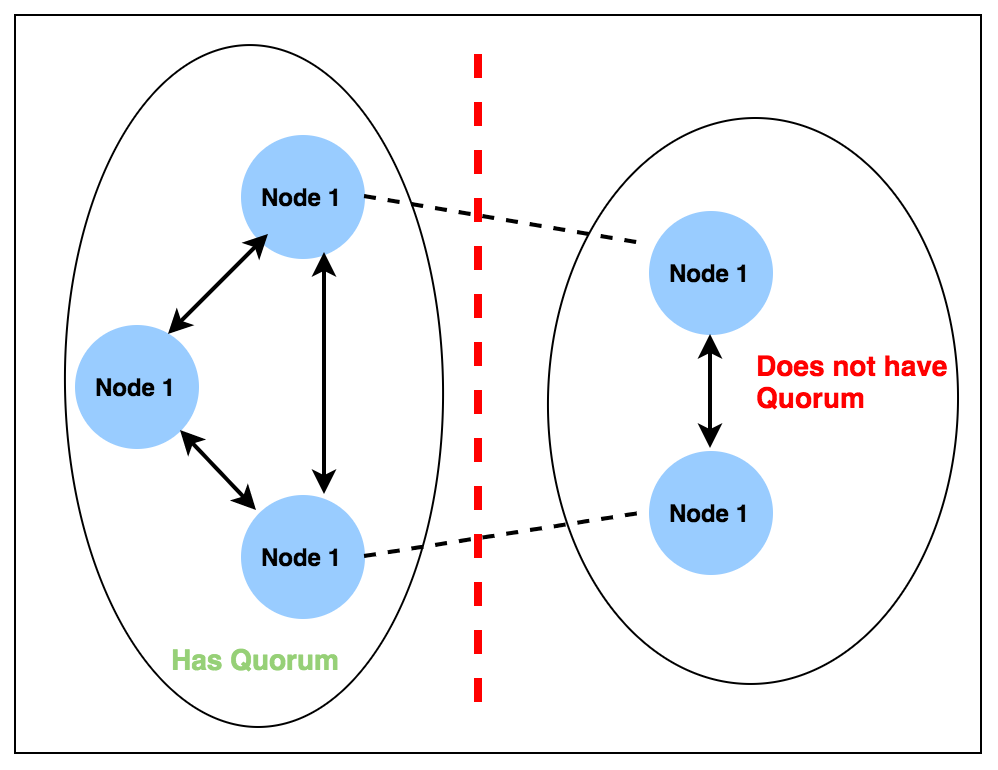
3개의 복제본으로 구성된 시스템에서 쓰기는 2개의 노드(2개의 쿼럼)에서 완료되어야 하고, 읽기는 2개의 노드에서 데이터를 검색되어야 한다.
일반적으로 총 시스템의 복제본 $V$에 대하여 모든 읽기 요청에 대해 읽기 쿼럼 $V_r$ 을 얻어야 하여 쓰기 요청에 대해선 쓰기 쿼럼 $V_w$ 얻어야 하는데, 이때 쿼럼의 값은 다음과 같은 속성을 따른다.
- $V_r + V_w > V$
- $V_w > V_/ 2$
첫 번째 규칙은 두 작업을 통해 데이터 항목을 동시에 읽고 쓰지 않도록 보장한다.
두 번째 규칙은 적어도 하나의 노드가 두 개의 쓰기 작업을 모두 수신하고 이에 대한 명령을 부과하도록 보장한다. 이는 서로 다른 두 작업의 두 쓰기 작업이 동일한 데이터 항목에서 동시에 발생할 수 없음을 의미한다.
두 규칙 모두 연관된 분산 데이터베이스가 중앙 집중식 단일 복제본 데이터베이스 시스템으로 작동하도록 보장한다.
참고